How we built an AI assistant that cut clinical trial setup from days to minutes

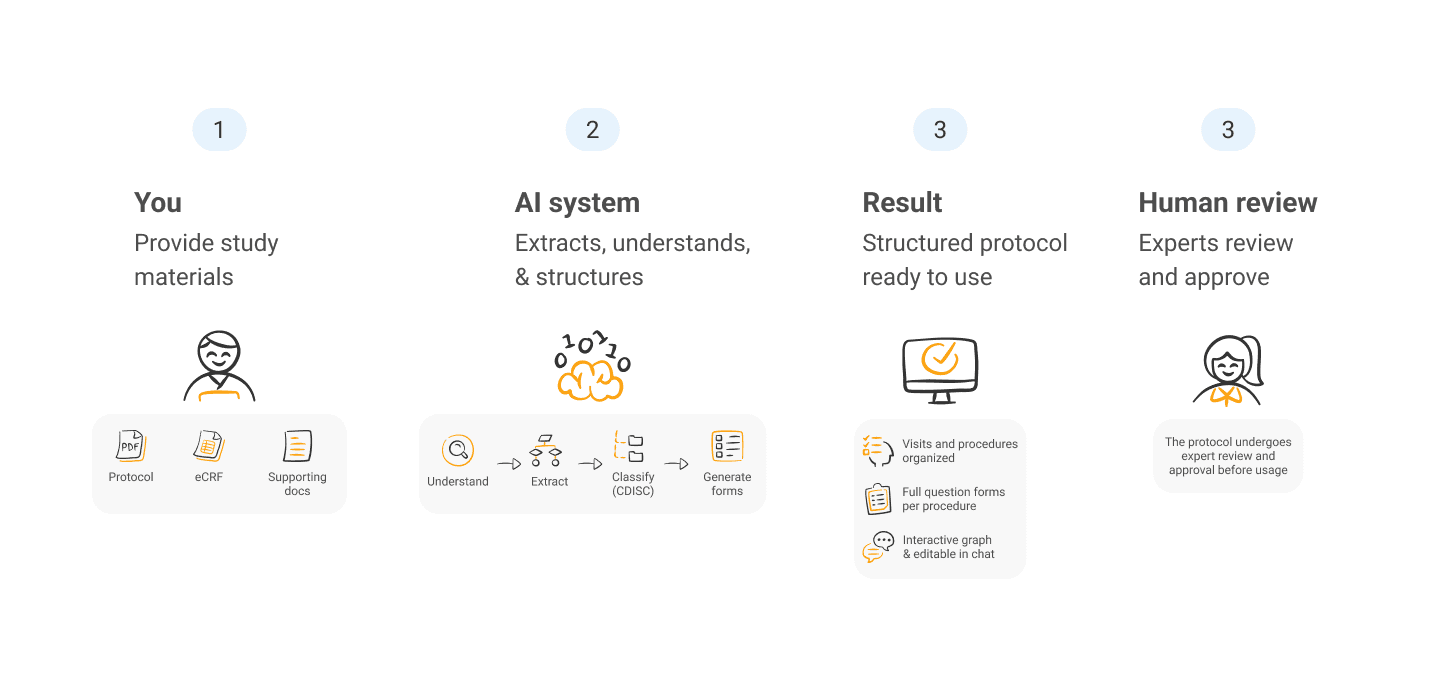
Before a single patient enrolls, someone has to turn protocol documents into a structured workflow in the app. It takes days and keeps specialists away from higher-value work. We built an AI assistant that reads the sponsor-provided documents and turns them into a complete, editable draft. So the week of setup becomes a quick review.
TL;DR | |
What | An AI assistant that reads clinical trial documents (150+ pages) and automatically turns them into a fully structured, editable protocol draft. |
Why it matters | Slow setup delays everything: trial start dates slip, costs grow, and fewer studies get off the ground. Faster setup means more trials, sooner. |
What changed | Specialists no longer protocol details from documents into the system by hand. They open a ready draft and refine it, so they have more time for decisions that require real clinical expertise. |
Result | The prototype won stakeholder buy-in at the hackathon. |
The problem no one had time to fix
Think back to the race to develop COVID-19 vaccines. Millions of people waited anxiously as clinical trials raced against time. And before a single patient could be enrolled, someone had to build a protocol: every visit scheduled, every procedure mapped, every data field configured. All of it by hand, from a pile of dense documents.
Usually, clinicians receive the study package for a new drug trial: a clinical trial protocol document, supplementary materials, and eCRF guidelines. Buried somewhere across those documents is the full roadmap of the trial.
Their job is to read all of it, translate it into a configured protocol inside the clinical trial management system, and get it exactly right. Get it wrong, and you get a protocol deviation, which can compromise trial data or trigger regulatory issues.
In numbers: the status quo
4–5 business days for an average protocol, v1 only | 150+ pages of source documents to read and interpret | 0 reusable work; every new trial starts from scratch |
In this article, we'll take you behind the build: how we solved the problem, the architectural choices we made, and what it means for the future of clinical trial setup.
What is a clinical trial protocol?
A clinical trial protocol is the plan for how a study will run. It has three layers.
VisitsThe sequence of patient appointments (e.g., "Pre-Screening", "Screening", "Week 4", "Follow-up"). Some visits depend on others and must happen in a specific order. |
ProceduresThe tasks performed at each visit (e.g., "Vital Signs", "Informed Consent", "Blood Draw", "ECG"). Each task follows the CDISC standard for clinical data collection. |
Questions and form fieldsEach procedure is a form with fields for text, dropdowns, checkboxes, and dates. |
A typical real-world protocol has 50–80 procedures spread across 20–40 visits, with each form containing 5–30 questions. So, the complexity adds up fast.
Why is manual setup so hard
The challenge isn't any single step; it's the volume of detail where mistakes aren't an option.
Volume | 150+ pages of source material with scattered information. |
Time | Setting up the first version takes 4–5 business days on average. |
Tedious and routine | Specialists spend time on manual transcription instead of higher-value clinical decisions. |
Risk of human error | Inconsistent naming, incorrect schedule, or missed procedures lead to costly mid-trial fixes. |
Inconsistent formatting | "Blood Pressure" in one sponsor's document is "BP Measurement" in another. Specialists standardize these terms manually every time. |
Poor standards adherence | Procedures and fields should follow CDISC standards, but manual setup often leads to inconsistencies. |
Limited scalability | Every additional study requires more people. You can't scale the work without scaling the team. |
Slow onboarding | The nuances take significant time to learn. New staff require significant time to learn the nuances. |
The idea: Let AI do the heavy lifting
The idea of using AI for protocol setup existed long before the hackathon. The problem was clear, and so was the potential value. But the implementation was complex, so it kept getting pushed aside.
The hackathon gave the team a safe space to test it fast, without production constraints. The challenge came directly from the client's own problem statement.
The core bet: if AI produces a good enough draft, specialists only need to review and refine it rather than build everything from scratch. That shifts the bottleneck from creation to review.
What we built: Clinical trial protocol drafting assistant
We built an end-to-end pipeline that takes one or more PDFs and produces a fully structured protocol draft. The result appears as an interactive graph: visits as nodes, dependencies as lines, and procedures inside each visit. A chat interface lets specialists rename procedures, add visits, or move questions.
Technical stack
LLMs | Claude Sonnet 4 and Claude Haiku 3.5, accessed via AWS Bedrock through LangChain. |
Orchestration | LangGraph, with both Python and TypeScript implementations. |
PDF parsing | PyPDF2 for text extraction, Camelot for tables. |
Visualization | Vite + React Flow for the interactive protocol graph. |
Why standard RAG doesn't work here
The most obvious approach for large documents is RAG (Retrieval-Augmented Generation): split documents into chunks, index them, and retrieve relevant pieces when needed.
But there’s a problem: RAG only works if you already know what to look for.
Ask, “What procedures are in this trial?” and almost every chunk looks relevant. Ask, “What happens at Week 4?” and the system first needs to know that Week 4 is even a visit. It's a chicken-and-egg problem: you can't retrieve the right information until you've already built the protocol you're trying to build.
The Map-Reduce approach
Instead of retrieval, the pipeline reads every page of every document and processes it in two stages.
Map
The LLM processes each page independently and extracts only protocol-related information: visits, procedures, schedules, and form fields. It ignores administrative content, legal text, and contact details. Hundreds of pages are compressed into a compact set of structured summaries.
Reduce
The LangGraph pipeline uses those summaries to:
extract visits,
identify procedures,
build visits in parallel,
classify procedures by CDISC domain,
generate forms,
assemble the final protocol.
The full pipeline:
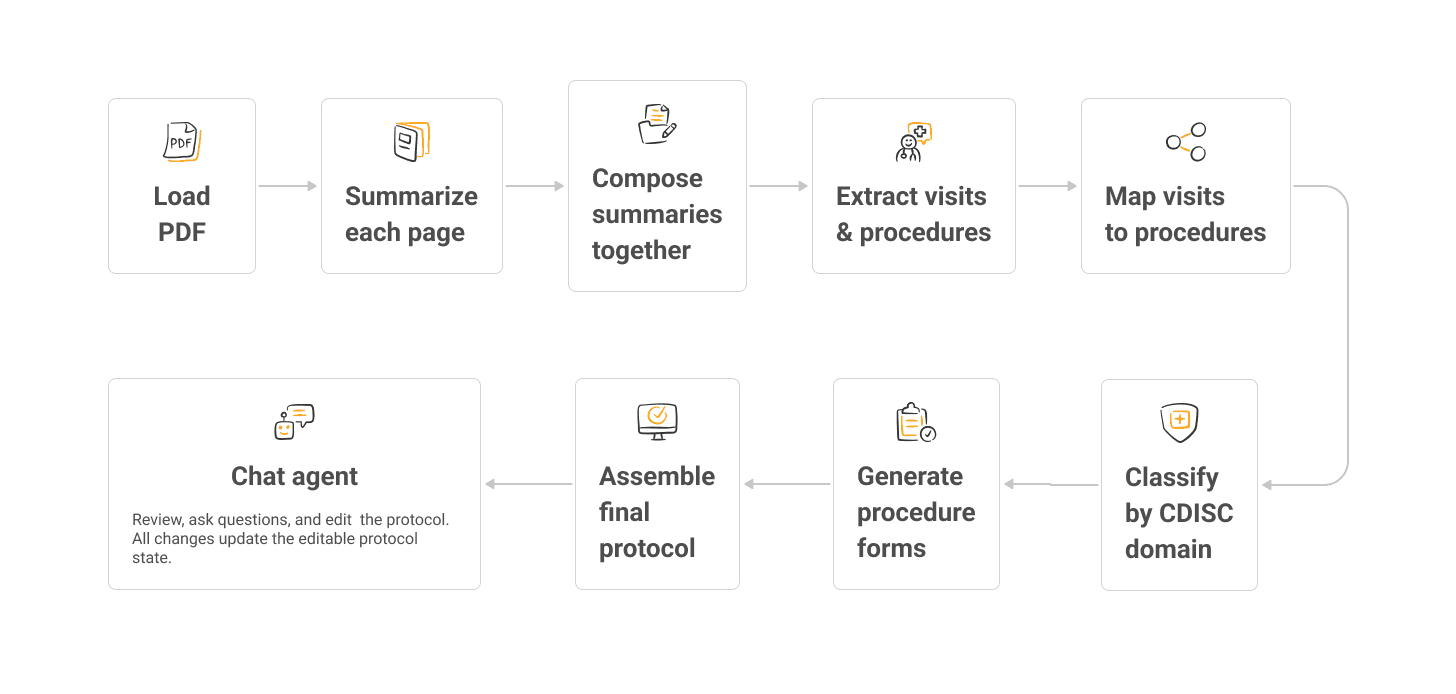
Each extracted procedure links back to the exact source pages where it appeared. When the system builds the procedure form, it sends the AI only those relevant pages instead of the full document. This reduces hallucination and keeps each step focused.
What changed for the business
We tested the assistant against protocols already configured in production, known ground truth. The AI matched closely on visit structure, dependencies, and procedure assignments.
Where gaps appeared, they were system-specific details not in the source documents, easy for a reviewer to catch and fill before enrollment begins.
The benefits add up quickly.
ThroughputMore studies run in parallel without growing the setup team proportionally. | ConsistencyCDISC classification applied uniformly; procedure naming consistent across visits. |
QualityReviewing a draft catches errors more reliably than building from a blank slate. | OnboardingNew team members can review an AI draft faster than learning to build from scratch. |
ScalabilityYou're no longer limited by how many people you have, just how fast they can review. | Sponsor satisfactionFaster, more reliable delivery means earlier start dates for studies. |
The same work that required 4–5 days of specialist time is in minutes. The same team handles more studies simultaneously. And because the AI applies the same naming conventions and CDISC classifications every time, consistency no longer depends on who built it.
From hackathon to production
During the hackathon, the team built and demonstrated the prototype. Both the client and internal teams quickly aligned around the idea.
After the presentation, the team moved the project into active development. They refactored and expanded the codebase, recreating the original Python prototype in TypeScript using the same LangGraph architecture.
Key takeaways
Protocol setup is a genuine bottleneck
It sits on the critical path before any patient can be enrolled. Any tool that shortens it creates immediate, measurable value.
This is a strong AI use case
The task is document-to-structure extraction with a well-defined output schema. Complex enough to challenge junior staff, regular enough to be learnable by an LLM.
Map-Reduce beats RAG for this kind of task
When you don't know what to search for until after you've built what you're trying to build, retrieval doesn't work. Reading everything and distilling it is the right architecture.
MVP discipline is everything
PDF in, structured protocol out, editable via chat. That scope was achievable in a hackathon window and enough to secure production investment.
What’s next?
We are working on deeper integration with clinical trial management systems, support for scanned PDFs, and improved handling of complex multi-column layouts.
FAQ
What is clinical trial protocol automation?
It's the use of AI to read clinical trial documents and automatically produce the structured protocol configuration that specialists would otherwise build manually.
How long does protocol setup take without AI?
At least 4–5 business days for an average study. Complex studies take longer. And that's just for the first version before revision rounds.
How long does it take with AI?
The pipeline processes 150+ pages across multiple files in minutes. Human review of the resulting draft takes a fraction of the time required for manual setup.
Can AI replace clinical experts?
No, and it's not designed to. The AI produces a draft; the expert reviews, adjusts, and approves it. The change is that their time goes toward high-value reviews rather than low-value transcription.
Is AI reliable for healthcare workflows?
VITech is HITRUST-certified, so reliability comes from design: structured output schemas, self-healing parsers that retry malformed responses, targeted context delivery, and mandatory human review before any protocol reaches production. The AI handles the volume, while specialists validate the results.

Share post


